Hadoop伪分布式部署
2. Hadoop 为分布式运行环境搭建
环境说明:
| 容器 | 容器ip |
|---|---|
| master | 192.168.1.210 |
2.1 基础环境配置
2.1.1 配置主机名
hostnamectl set-hostname master && bash2.1.2 修改hosts,添加映射,关闭防火墙
修改hosts
添加如下:
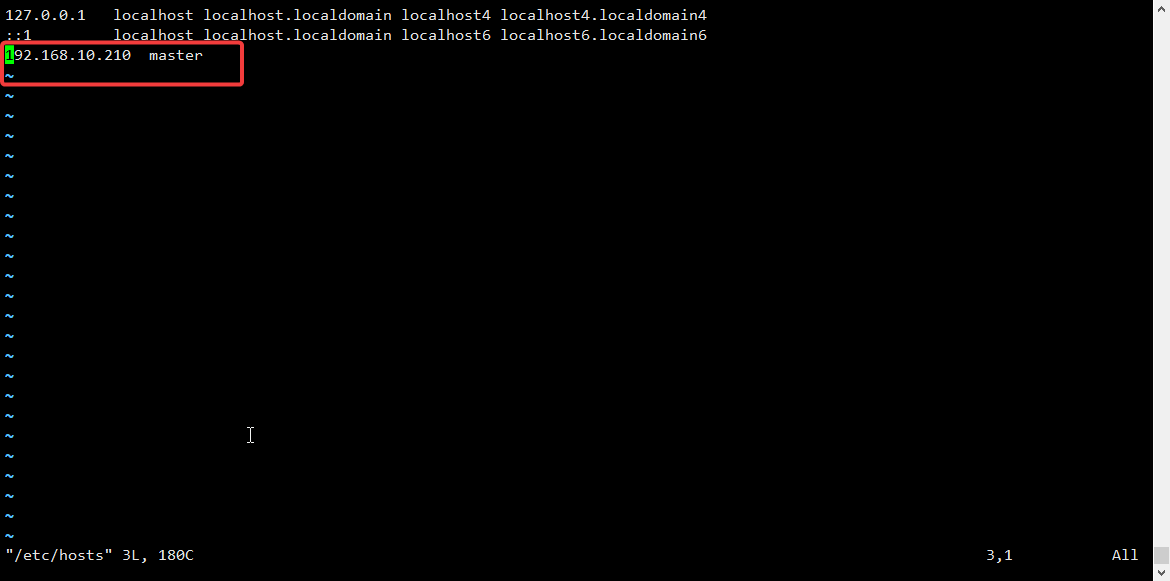
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.210 master关闭防火墙
systemctl stop firewalld
systemctl disable firewalld查看防火墙状态如下:
[root@master ~]# systemctl status firewalld
2.1.3 生成免密公钥
[root@master ~]# ssh-keygen -t rsa #然后一直回车
或者
[root@master ~]# ssh-keygen -f ~/.ssh/id_rsa -P '' #免回车
2.1.4 复制公钥到服务器
ssh-copy-id master
2.1.5 JDK配置
解压文件到相应的位置:
[root@master ~]# tar -zxvf /opt/software/jdk-8u162-linux-x64.tar.gz -C /opt/module/
[root@master ~]# cd /opt/module/ #进入解压目录,可以给解压后的文件改个名字,方便记忆
[root@master module]# mv jdk1.8.0_162/ jdk设置jdk环境变量:
[root@master module]# vi /etc/profile在末尾添加如下配置:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin刷新环境变量:
[root@master module]# source /etc/profile配置完后即可查看jdk版本号:
[root@master module]# java -version
基础环境搭建完成!!
2.2 Hadoop伪分布数环境搭建
前提:已完成免密登录,jdk配置
2.2.1 解压包到相应位置:
[root@master module]# tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
[root@master module]# mv hadoop-3.1.3/ hadoop #改一下名字,方便记忆2.2.2 添加hadoop环境变量
[root@master module]# vi /etc/profile在末尾添加以下内容:
#HADOOP
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
:wq 保存退出后,刷新环境变量:
[root@master module]# source /etc/profile配置好后,即可直接查看hadoop 版本号
[root@master module]# hadoop version
2.3 修改6个主配置文件
- :one: core.site.xml
- :two: hdfs-site.xml
- :three: mapred-site.xml
- :four:yarn-site.xml
- :five: hadoop-env.sh
- :six: workers
2.3.1先进入配置目录
[root@master module]# cd hadoop/etc/hadoop/
[root@master hadoop]# ll可以看到如下文件:
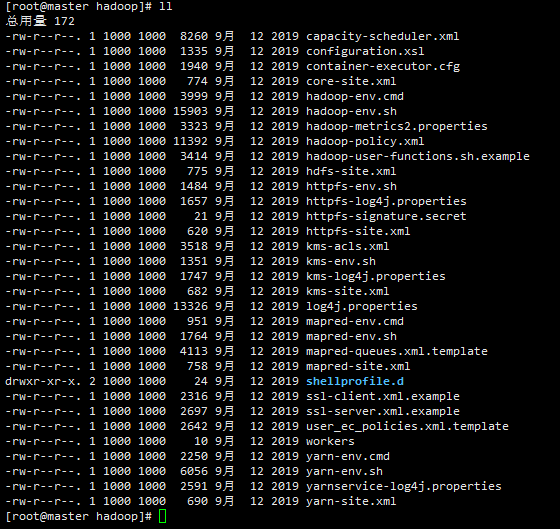
我们只用修改其中的6条
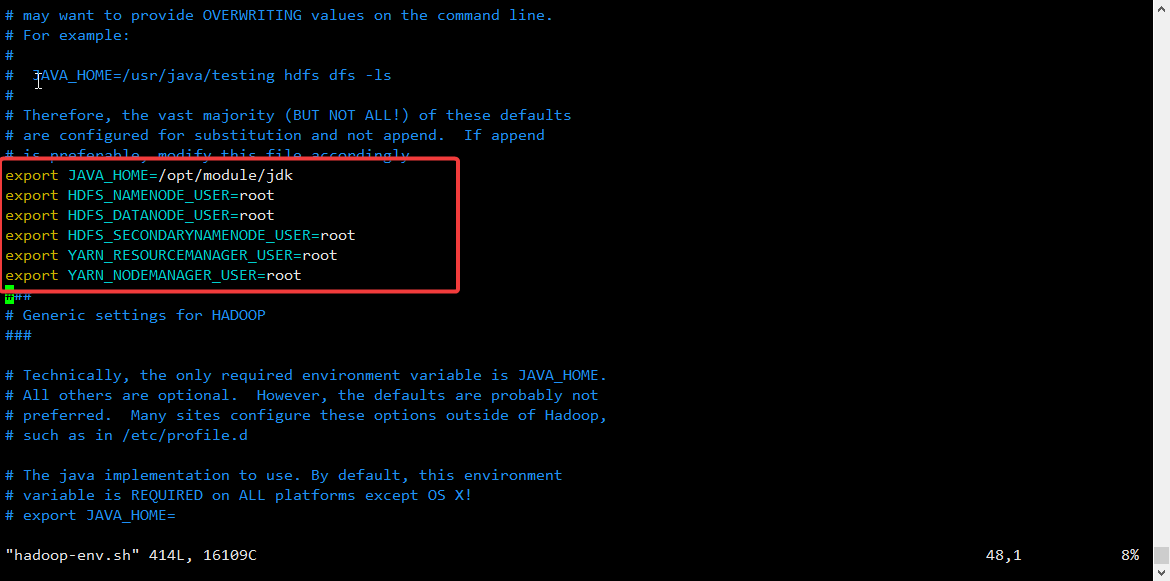
2.3.2 hadoop-env.sh配置:
[root@master hadoop]# vim hadoop-env.sh #告诉hadoop jdk在哪里export JAVA_HOME=/opt/module/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#备注:3.0后的版本需要指定服务用户如下:
2.3.3 workers配置
(根据自己的集群来进行配置):
[root@master hadoop]# vi workers
master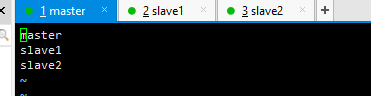
2.3.4 core.site.xml配置:

[root@master hadoop]# vi core-site.xml<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopdir/tmp</value>
</property>
</configuration>2.3.5 hdfs.site.xml:
[root@master hadoop]# vi hdfs-site.xml <configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopdir/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopdir/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!--是否开通HDFS的Web接口,3.0版本后默认端口是9870-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>2.3.6 mapred-site.xml:
[root@master hadoop]# vi mapred-site.xml <configuration>
<property>
<!-- 指定mapreduce 编程模型运行在yarn上 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2.3.7 yarn-site.xml:
[root@master hadoop]# vi yarn-site.xml<configuration>
<property>
<!-- 指定mapreduce 编程模型运行在yarn上 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>以前hadoop 2.X 版本,访问web界面,hdfs端口号是50070,现在3.X版本,端口号是9870(最好自己指定端口号)
2.3.8 配置好后分发到副节点(别忘了环境变量也要再次分发):
伪分布式忽略
分发完后去副节点刷新环境变量
2.3.9 初始化namenode:
[root@master ~]# hdfs namenode -format结果:
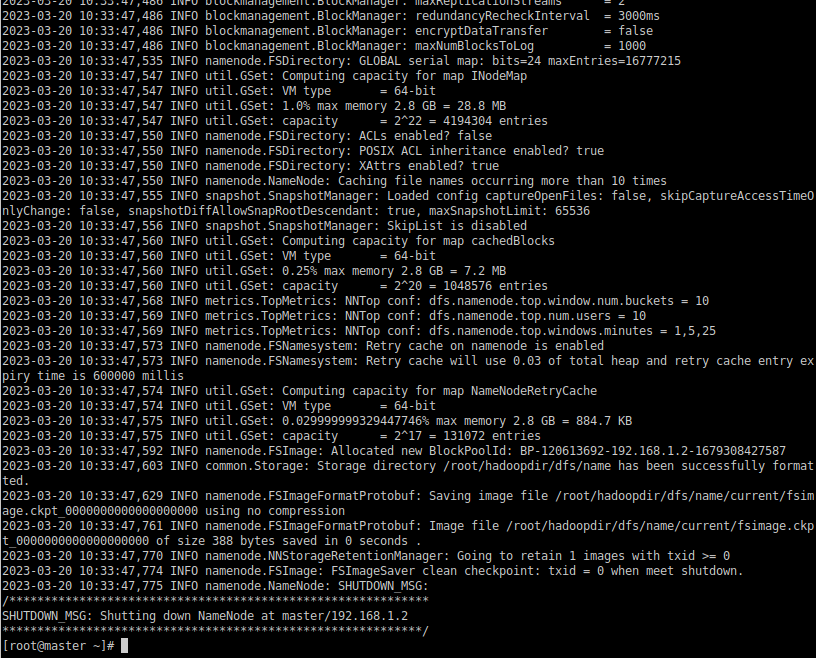
2.3.10 开启集群:
简易启动:
[root@master ~]# start-all.sh 查看结果:
[root@master ~]# jps
3680 SecondaryNameNode
3236 NameNode
3435 DataNode
4571 Jps
3981 ResourceManager
4157 NodeManager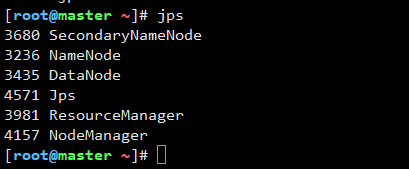
2.4 web端口访问测试
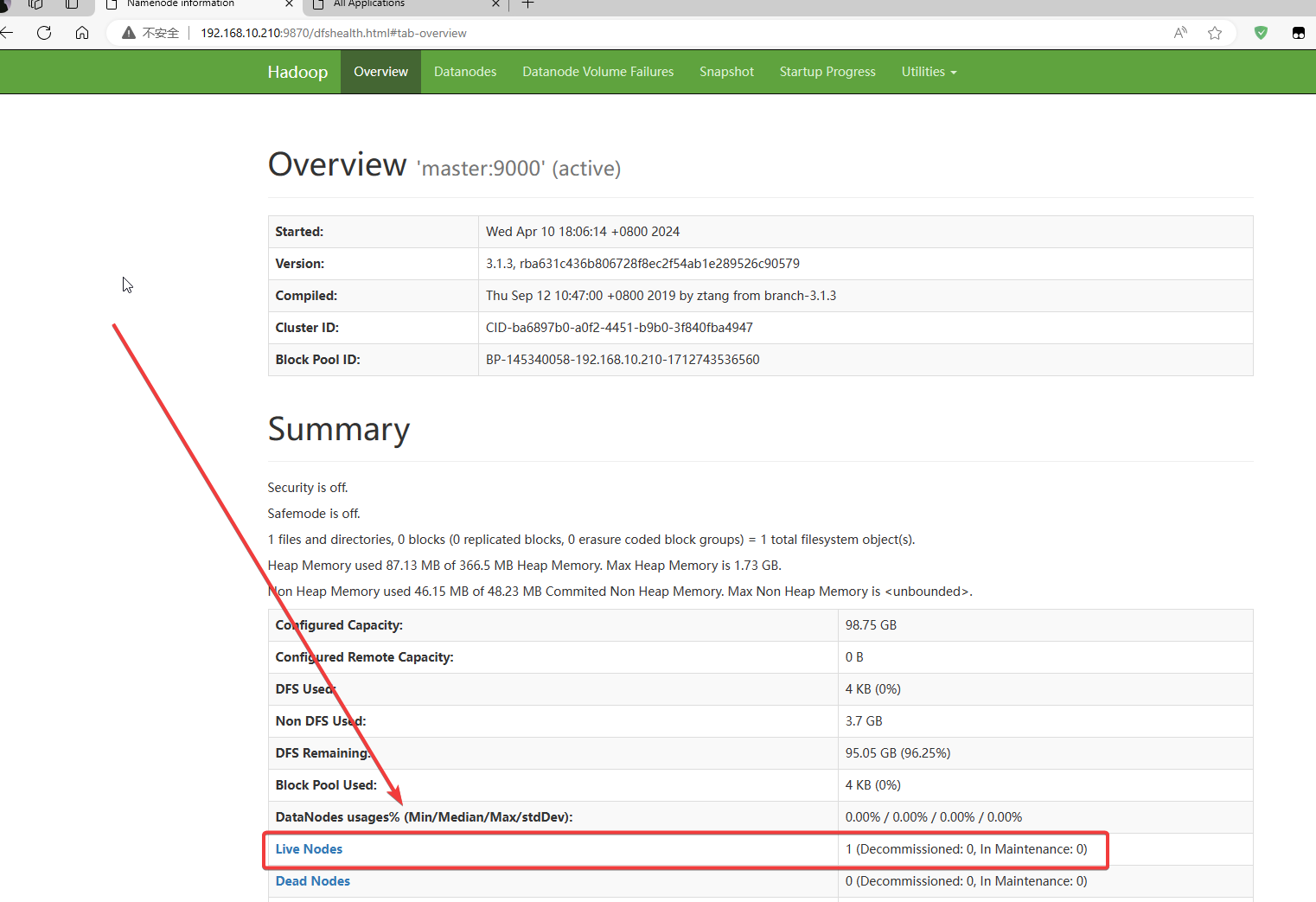

完成



